
My take on Continuous Integration
The essentials of Continuous Integration (CI) have been summarized by Martin Fowler. Following is my take on a few principles, practices and/or considerations that have served me well over the years.
Integrate continuously
It looks quite silly writing this, but Continuous Integration is about… continuously integrating software! Trunk Based Development is thus a very natural fit.
Of course I have been told that this is not the way you do things, meaning GitFlow is the only true way. Let the creator of this model answer to that:
Just updated my git-flow blog post after some orange site fuss yesterday with a bit of nuance that hopefully lets everyone interested make their own decisions for adoption.https://t.co/pbsp8kK10R pic.twitter.com/FeahNeOkm5
— Vincent Driessen (@nvie) March 5, 2020
Build in 1 step
This one is literally step 2 of the Joel Test (written in 2000 by the way: how much do you score today?).
I will just add that to me every developer should be able to perform this step locally:
- it is another way to write: don’t let YAML become the language of choice for your build. Don’t get me wrong, YAML has a fine syntax for configuring systems (and it has comments!). But it cannot properly describe your build for several reasons:
- it is tied to the CI tool you are using. AppVeyor syntax is different from Travis CI which is different from other vendors. Why lock yourself in?
- a complex configuration is hard to describe (and harder to understand) in YAML. There are so many expressive languages and tools nowadays to describe a build that are intimately tied to your platform of choice that it is almost ridiculous: Ant (the precursor), MSBuild, Gulp, Grunt, Maven, Gradle, Phing, Rake, Cake, Psake… Or at least please revert to the good old Makefile!
- if the software you are building must be built cross platform, do yourself a favor and pick up a tool that natively supports that (and most have been since Ant).
- executing your build locally means you can actually test it before you send your changes to the CI platform. This is especially valuable when you want to change the behavior of your build without having the whole team take a day off while you debug the build directly on the CI platform.
- developers have access to the code of the build and they can act on it. Surely this must be the first step of what they meant by DevOps…
- in the very highly improbable case where you have to urgently build a new version of your software while your CI tool is down, well now you can. I have already been saved by this feature.
Ensure quality
Your build should ensure a certain level of quality of your source code (ie internal quality). There are multiple ways to do that and one should use as many as possible:
- compilation (for languages for which it is relevant, of course).
- static analysis is indispensable for interpreted language (like ESLint for JavaScript or Rubocop for Ruby) but can also be invaluable for compiled languages. I used to love Cppcheck back in the day and I have had a pretty good experience integrating SonarSource on my C# codebase.
- The same goes as for compilation warnings: activate as many checks as possible, as early as possible, and treat them as errors. Nobody wants to correct 100s of warnings on a large codebase (and nobody does), and if you let too many warnings creep in you will not notice the occasional important new message in the middle of all the unimportant stuff.
- automated tests, because that is exactly what they are here for. More on them later.
- While you are at it, code coverage is a very relevant indicator of quality: though 100% code coverage does not necessarily mean much, 0% tells a lot about the quality of your codebase!
Be as strict as possible about what indicator changes should result in a failed build. If you are not, metrics will slip away (like code coverage for instance) and become useless.
Build fast
Continuous means that a new build should be performed every time a developer pushes her changes to the repository. If there is a problem with those changes:
- she wants to know as fast as possible while the changes are fresh in her mind.
- her teammates want to know if they can safely synchronize with the remote. Failing to do so could result in the whole team being unable to work (because of a failing test for instance).
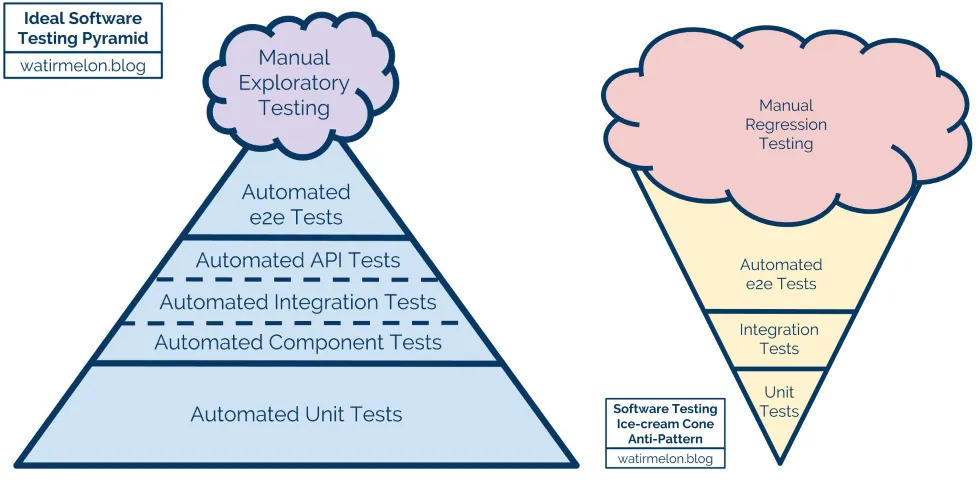
In most cases this means that the build should distinguish between fast checks that can be performed every time and slow checks that could be performed asynchronously (think Nightly Builds). This usually means distinguishing Unit Tests from Integration Tests. Continuous Integration is thus very beneficial to the proud owners of a tests pyramid (as opposed to the owners of a tests ice-cream cone):
Create deployable packages
If all of the above is in place, everything left to do is create deployable packages. What do I mean by that?
A deployable package is a complete and configurable archive containing all the necessary files for the project to run.
- Complete means it contains:
- compiled (and/or minified) sources.
- assets.
- dependencies.
- I guess I am not a strong believer in the manual merging of lock files…
- This way you can avoid having to fetch dependencies after every deployment:
- It may be problematic on the rare occasions when your dependency repository goes down…
- Depending on the way dependencies have been declared you may not be sure that what you are deploying is what you tested.
- Configurable means you can dynamically specify platform specific configurations at the time of installation (like a connection string to a database for instance):
- Web Deploy is the quintessence of a technology that allows that for web applications. I wish Microsoft would invest in making it more ubiquitous (targeting nginx for instance) and… easy to use…
- When possible (which is most of the times) my configuration is safely stored in one or several local files instead of potentially leaking environment variables.
Being complete and configurable, you can test the same package on different stages and really make sure of the quality of what is going to be deployed in Production. You can store those packages in a dedicated repository: GitHub Releases for instance. I say we are not far from Continuous Delivery (CD) there.
This also means that you do not have to install and configure Git on your Production servers.